
Everyone has been talking about MLOps for over a year now. I looked around for how the lifecycle and processes have evolved.
The discipline of seeking insight from data has been around for 25 years. Back then, it was known as data mining. In this article, I present a survey of the ML lifecycle process and conclude with my take on machine learning lifecycle for MLOps era. So if you are in a hurry, jump to the last section for TL;DR.
The broad steps in data mining/science have remained more or less the same:
- Understand domain or business problem
- Collect the needed data from a variety of sources
- Curate the data, clean and label it
- Transform the data, harmonize it, and shape it
- Explore and visualize the data
- Train a model, validate it, and tune hyper-parameters
- Use or deploy the models
But the nature of data, processing, and applications has changed significantly:
- Scale: The amount of data analyzed has increased manifolds.
- Widespread Use: ML-powered applications are part of our daily lives and we critically depend on them.
- Batch vs. Online: The models were used earlier in batch mode to draw insights and guide business decisions. Now more models are deployed to serve inference at scale.
The evolution can be roughly divided into 3 eras (timelines are overlapping):
- Batch Era: ETL pipelines brought data from operational systems to data warehouses and data marts, and data was mined thereafter.
- Big Data Era: Data became too big for warehouses of the time. Data streamed in data lakes, which often turned into swamps. Only a few organizations deploy online models.
- MLOps Era: Making it easy for everyone to deploy online models continuously.
Batch Era
You can call it ancient times. The internet was still in the nascent stages. Most enterprise applications were generating and processing data in batches.
The applications and data were siloed in various departments of an organization. The challenge was to bring it all together so that the whole is greater than the sum of its parts.
Data modeling “Schema-on-Write” was very important. Batch ETL data pipelines brought the data to a centralized Data Warehouse. It was aggregated and stored in data marts, each for a specific line of business, department, or subject area.
Data was not so big. RDBMS with column-oriented indexes were handy and OLAP Cubes ruled the day.
Data mining was mostly a backroom operation. Its role was to extract insights needed for making business decisions. So the processes of the time reflected this batch mode of data mining.
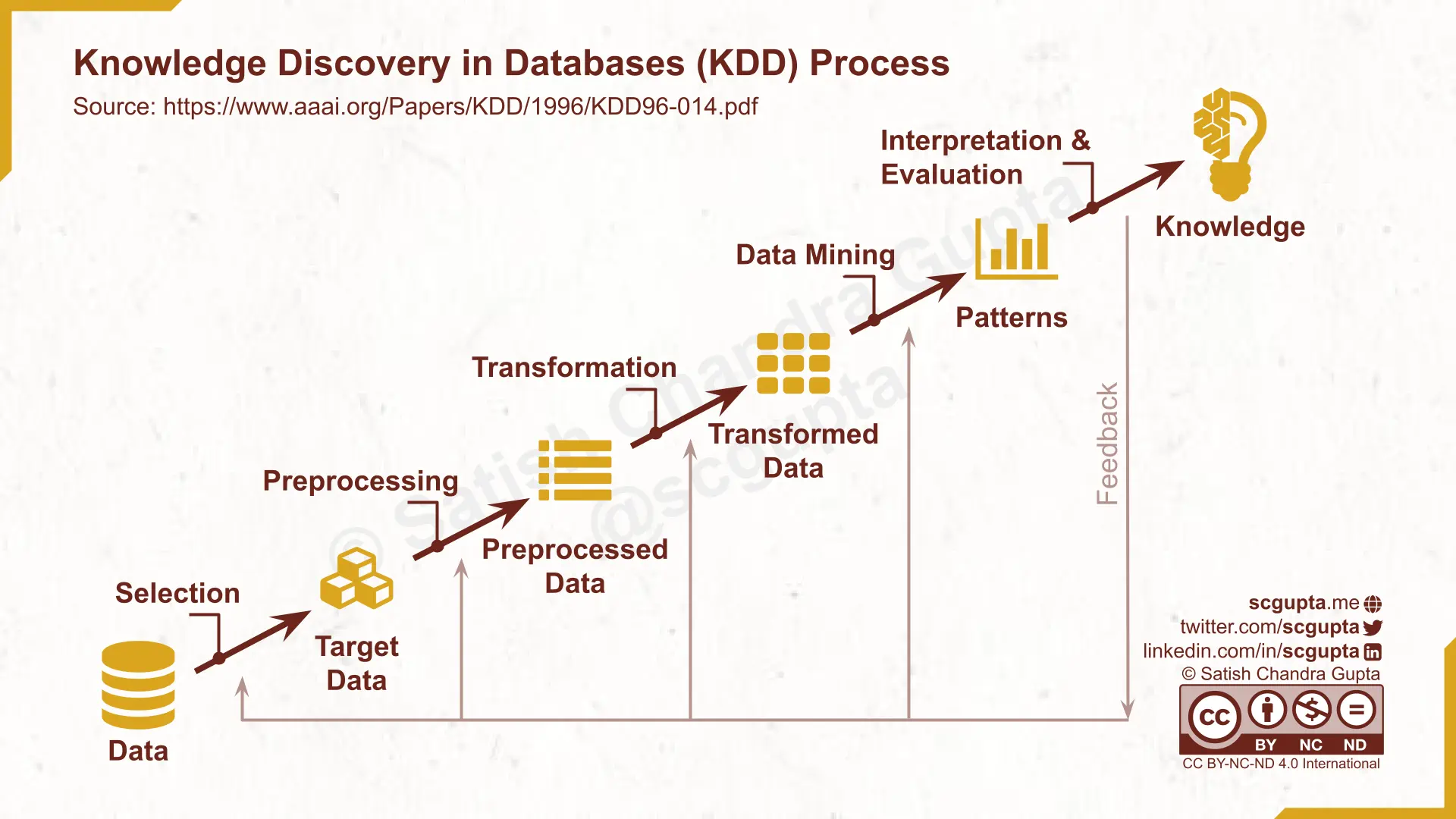
KDD: Knowledge Discovery in Database
Extracting insights from data predates Big Data. KDD Process (Knowledge Discovery and Data Mining: Towards a Unifying Framework by Fayyad et. al., 1996) was among the first to define a framework for data mining in databases. KDD process has 5 stages with feedback:
- Selection: Selecting a data set, a subset of variables, or data samples
- Pre-processing: Clean the data, handle missing values, etc.
- Transformation: Feature selection and dimension projection to reduce the effective number of variables.
- Data Mining: Apply a particular mining method, e.g., summarization, classification, regression, clustering.
- Interpretation & Evaluation: Extract patterns/models, report it along with data visualizations.
Modern data pipelines have pretty much the same steps.
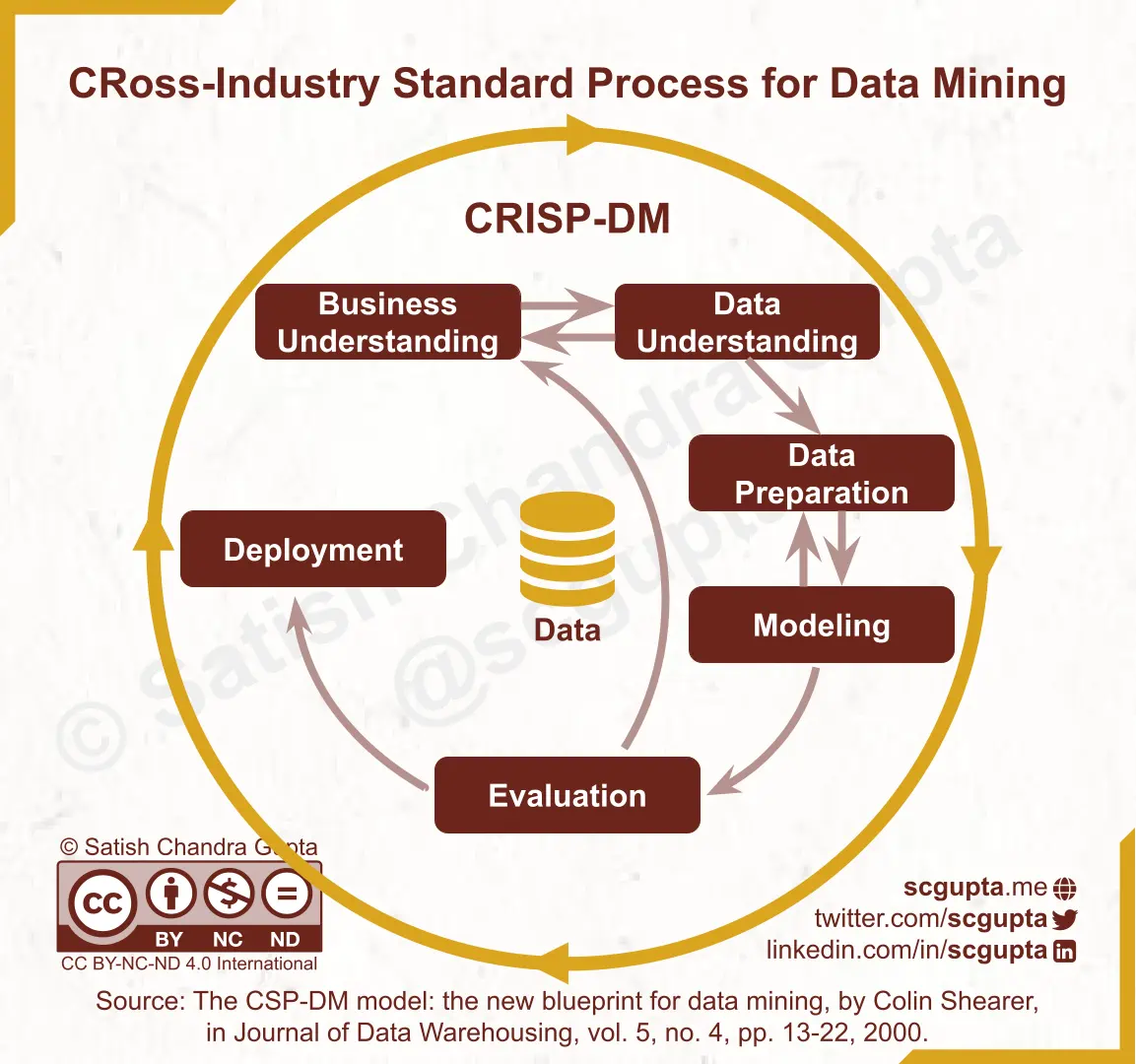
CRISP-DM: CRoss-Industry Standard Process for Data Mining
Then came the CRISP-DM process (The CRISP-DM Model: The New Blueprint for Data Mining by Colin Shearer, 2000), which remains influential even today (CRISP-ML(Q)). It describes how “data analysts” should start from business needs, mine the data, and “deploy” the model. It breaks the data mining process into six major phases:
- Business Understanding: Determine business objectives. Assess resources, requirements, constraints, risks, and contingencies. Define data mining goals and make a project plan.
- Data Understanding: Collect initial data, explore the data, and verify data quality.
- Data Preparation: Select and clean the data. Add derived attributes and generated records. Merge the data, and shape it as per the desired schema.
- Modeling: Build the model, and assess its quality.
- Evaluation: Review the model’s construction to ensure that it achieves the stated business objectives.
- Deployment: Generate a report, or implement a repeatable data mining process across the enterprise. Plan monitoring of the data mining results, and maintenance of the data timing process.
“Deployment” is where it was ahead of its time. There was no way to deploy a model as an inference function. It states (customer here refers to the customer of the analysts, i.e. business org/managers):
The knowledge gained must be organized and presented in a way that the customer can use it, which often involves applying “live” models within an organization’s decision-making processes, such as the real-time personalization of Web pages or repeated scoring of marketing databases.
Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process across the enterprise. Even though it is often the customer, not the data analyst, who carries out the deployment steps, it is important for the customer to understand up front what actions must be taken in order to actually make use of the created models.
SEMMA: Sample, Explore, Modify, Model, and Assess
SEMMA stands for Sample, Explore, Modify, Model, and Assess. It is a list of sequential steps developed by SAS Institute to guide the implementation of data mining applications.
- Sample: Sample and select data for modeling.
- Explore: Visualize data to discover anticipated and unanticipated relationships between data variables and identify anomalies.
- Modify: Select and transform data variables to prepare data for modeling.
- Model: Apply various modeling techniques to prepare data.
- Assess: Evaluate and compare the effectiveness of the models.
SEMMA stages seem to be somewhere between KDD and CRISP-DM.
Big Data Era
Data has an uncanny ability to outgrow any storage and processing technology. Big Data arrived and Data Warehouses were insufficient for processing the piles of data businesses were generating. So, we invented the Data Lake (blobs repository) to store raw data files at any scale. This led to the shift from “schema-on-write” to “schema-on-read”.
Very soon, everyone started dumping whatever data they felt like into the data lakes in whatever format/schema they fancied. Data Lakes turned into Data Swamp. Data abundance coexisted with the scarcity of usable data. Data Cleaning became a thing.
You can call it medieval times. The scale of data analytics and Business Intelligence grew manifolds. Data Scientist became the sexiest job.
The data collection and pipelines were automated and ran mostly at a daily cadence. Often, data analytics dashboards were updated in real-time joining batch and streaming data processing. But most organizations used predictive models in batch mode for guiding their business decisions and products, and only a few deployed ML models in production for online real-time inference.
The lifecycle and processes were adapted to include explicit steps for data pipelines, model training, validation, and even (manual) deployment.
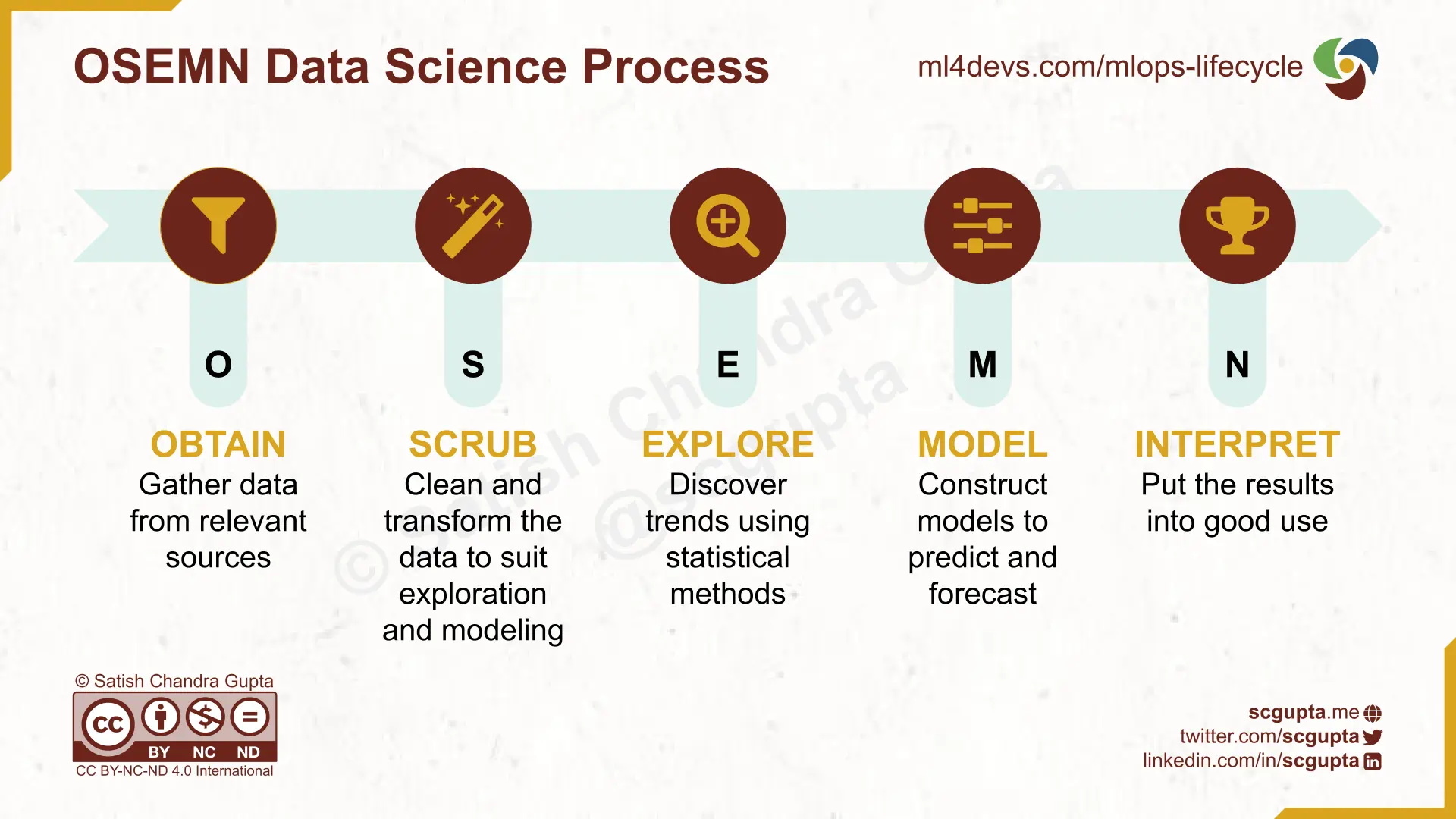
OSEMN: Obtain, Scrub, Explore, Model, iNterpret
Hilary Mason and Chris Wiggins described the OSEMN process in “A Taxonomy of Data Science” blog post (dated 25 Sep 2010). It has 5 steps: Obtain, Scrub, Explore, Model, and INterpret.
-
Obtain: Pointing and clicking do not scale.
Crawl or use APIs to automate data collection. -
Scrub: The world is a messy place.
Your model will be messy too unless you clean and canonicalize the data. -
Explore: You can see a lot by looking.
This is what we do in Exploratory Data Analysis (EDA). -
Models: Always bad, sometimes ugly.
Optimize the chosen loss function, and pick the best through cross-validation. -
Interpret: The purpose of computing is insight, not numbers.
Unlike arithmetics, statistical results require nuanced interpretation.
The blog is now defunct, but you can read it on the Web Archive. As you can see, it is still very much like KDD/CRISP-DM but the explanations of the steps reflect web-scale big data reality.
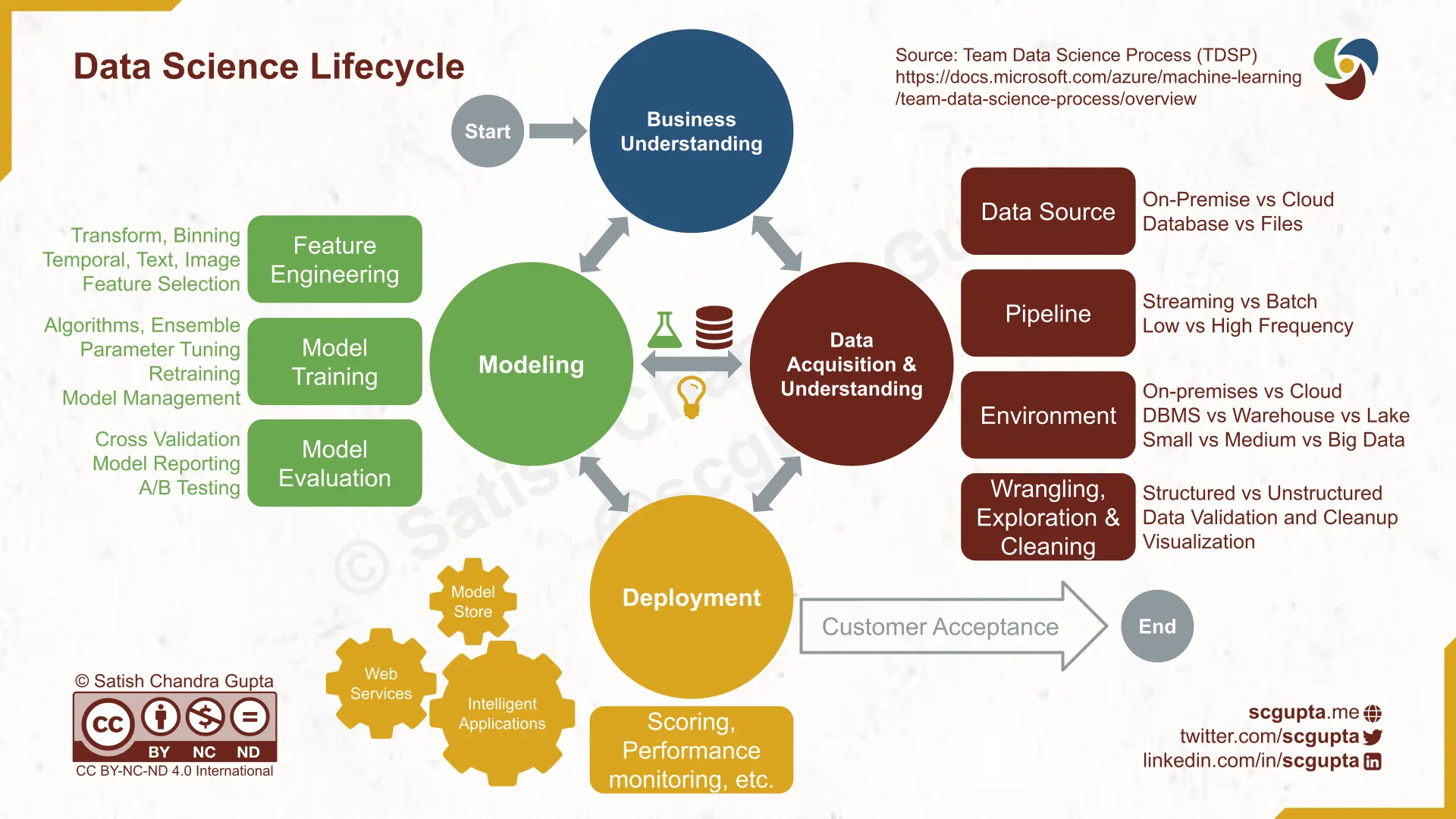
TDSP: Microsoft’s Team Data Science Process Lifcycle
Microsoft’s Team Data Science Process (TDSP) Lifecycle has four stages:
- Business Understanding
- Data Acquisition and Understanding
- Modeling
- Deployment
The “Data Acquisition and Understanding” and “Modeling” stages are further broken down into more detailed steps. It is envisioned as a waterfall model ending with Customer Acceptance, but it doesn’t require much imagination to extend it to be interactive.
It is pretty much what most companies currently follow knowingly or unknowingly.
In a paper at ICSE-SEIP 2019 conference, Saleema Amershi, et al. from Microsoft Research describe 9 stages of the machine learning workflow that is different from TDSP:
Some stages are data-oriented (e.g., collection, cleaning, and labeling) and others are model-oriented (e.g., model requirements, feature engineering, training, evaluation, deployment, and monitoring). There are many feedback loops in the workflow. The larger feedback arrows denote that model evaluation and monitoring may loop back to any of the previous stages. The smaller feedback arrow illustrates that model training may loop back to feature engineering (e.g., in representation learning).

MLOps Era
The rise of DevOps characterizes the modern era. When organizations regularly deploy ML models in production as part of their software applications/products, they need a data science process that fits into the DevOps best practices of Continous Integration and Continous Delivery (CI/CD). That is what is fueling the hype of MLOps.
Most companies are not yet there and may I dare say need it at present. Only big corporations like FAANG currently have a business that needs to deploy thousands of models every hour serving millions of end users. But as ML seeps into more applications, companies will begin to adopt a process with continuous training, integration, and delivery of ML models.
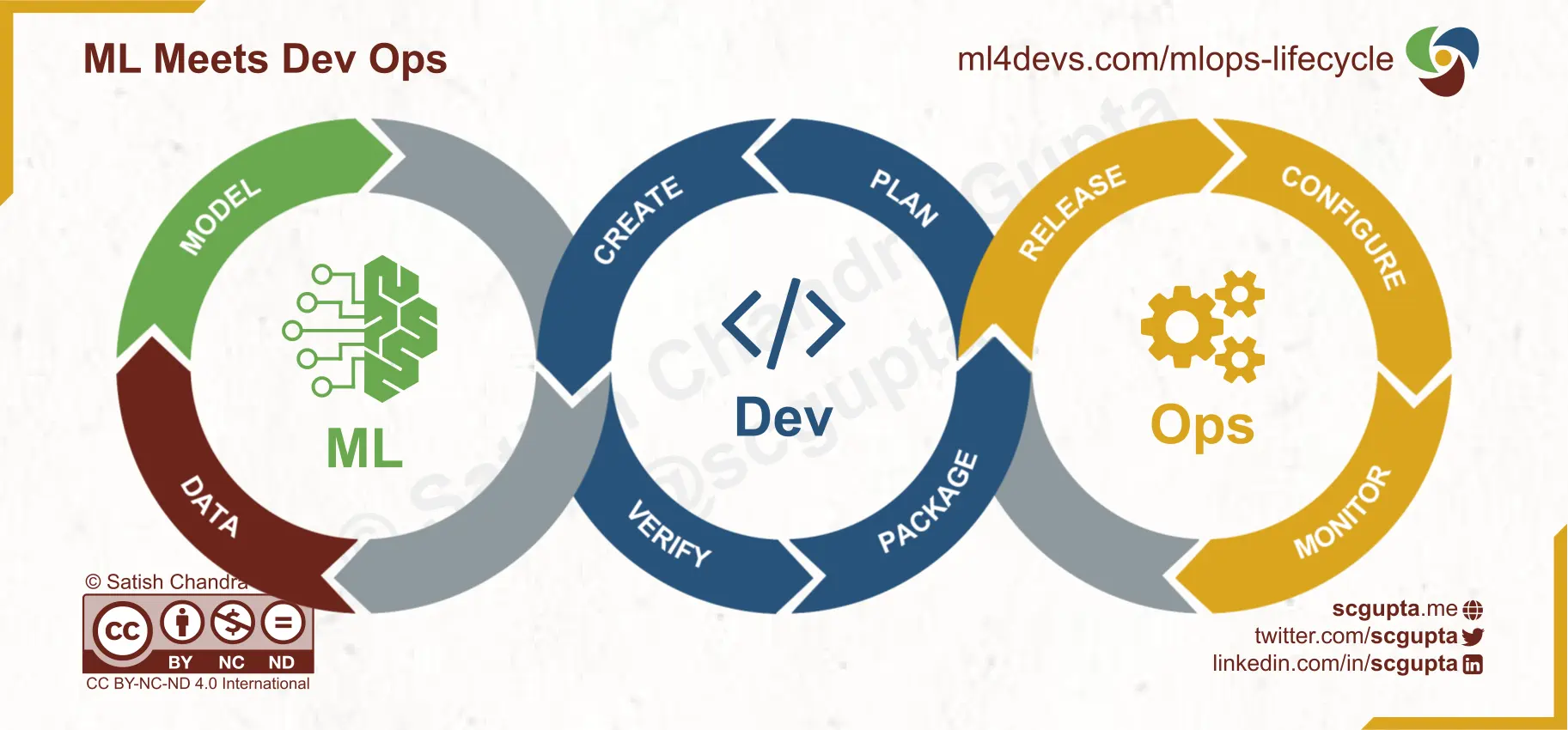
ML Meets DevOps: 3 Loops
An obvious way of blending ML into DevOps is to make the MLOps loop by adding ML to DevOps infinite loop and adapting Dev and Ops to suit data science.
Notice how this loop has the Data and Model as single steps characterizing the data processing and model building. On the other hand, the processes discussed so far dealt precisely with only these two steps. IMO, such dominance of Ops in a process is a step backward.
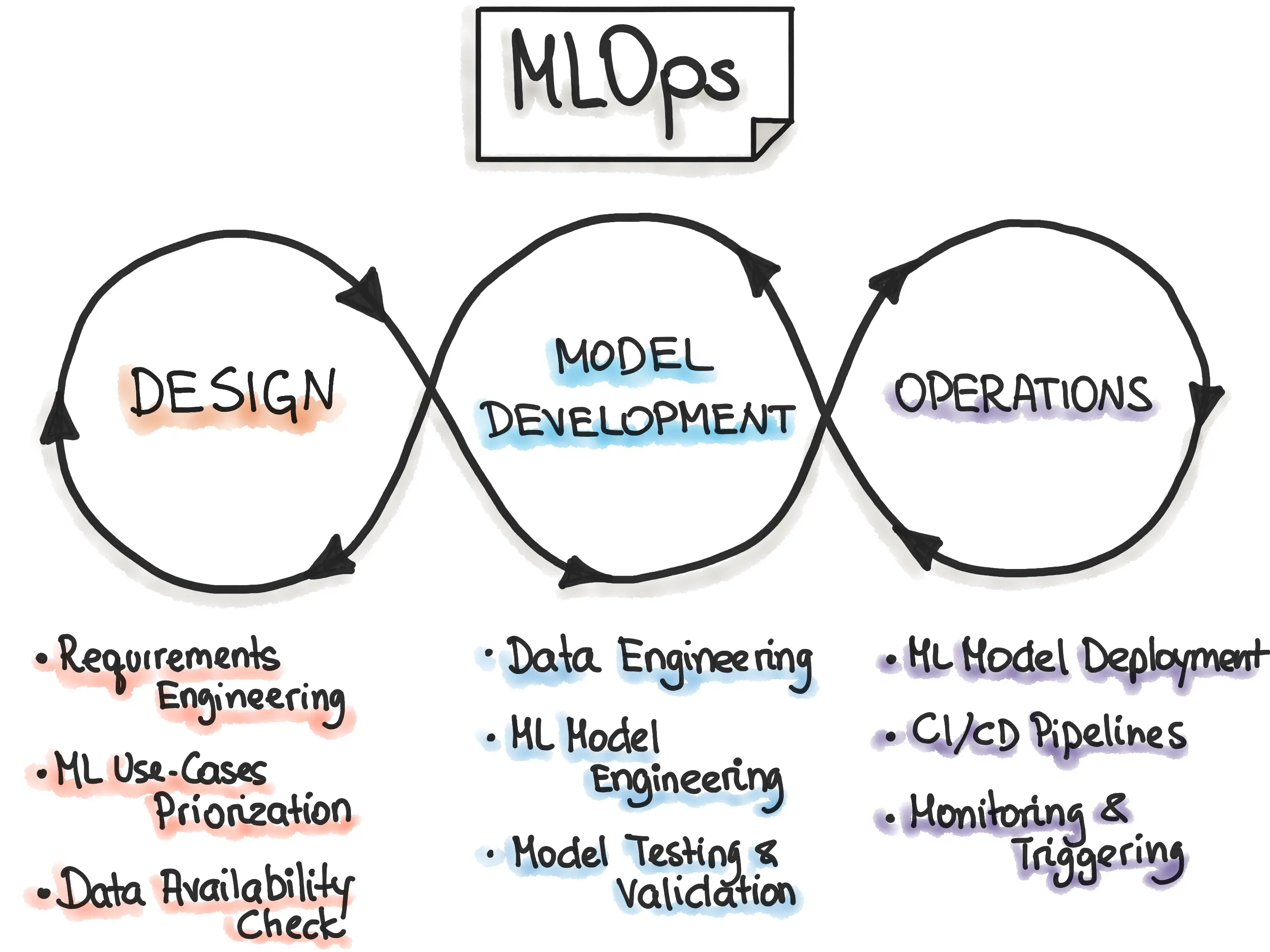
There are other attempts at a 3-hoop MLOps loop too. For example, the following captures the 3 broad phases Iterative-Incremental MLOps Process has three broad phases (which are still coarse IMO):
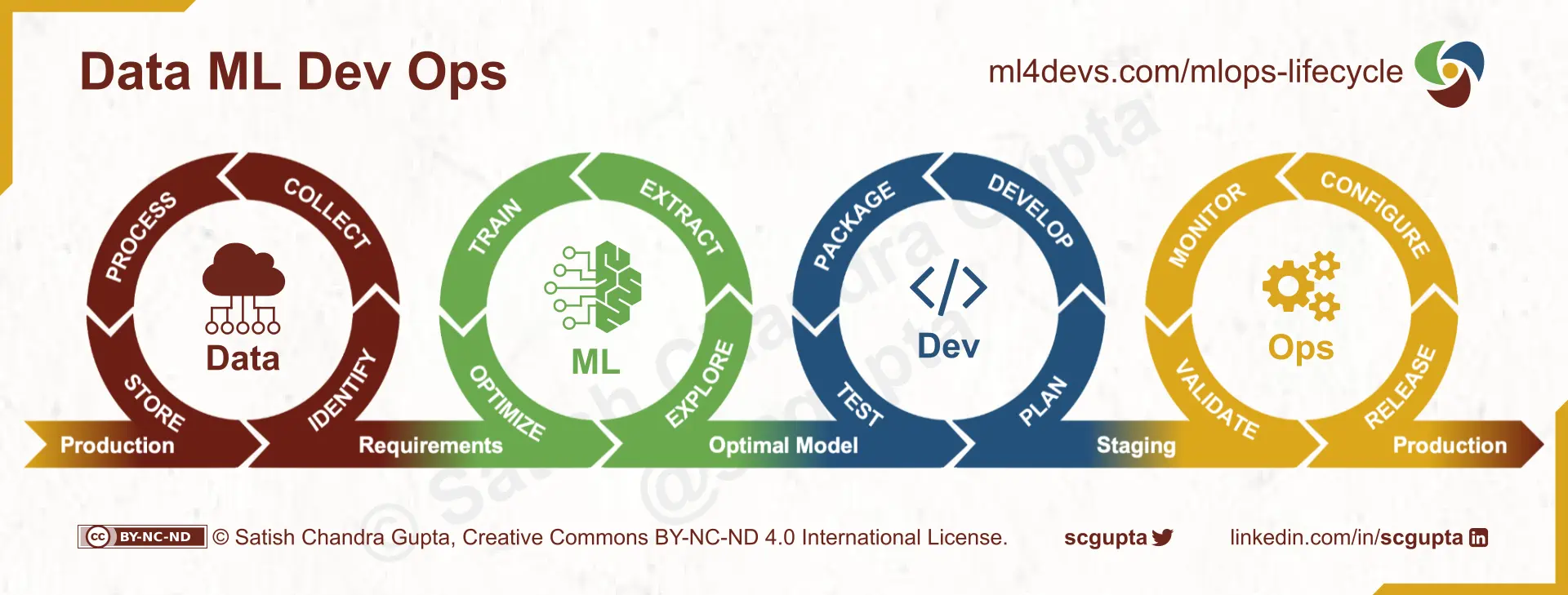
Data-ML-Dev-Ops Loop
A blog post by Danny Farah described the 4 loops of the MLOps lifecycle, one each for Data, ML, Dev, and Ops. I like it for two reasons:
- It retains the details of the data and ML steps
- It feels more familiar w.r.t. the DevOps infinite loop.
Similar to DevOps, but it still feels different. It is a missed opportunity to bring developers, data engineers, and data scientists to the same page. My 3 lessons for improving the success rate of ML projects are to consolidate ownership, integrate early, and iterate often. It is important to have a single lifecycle process that gives flexibility to all 3 to execute at a different cadence. Overall visibility to all stakeholders reduces the surprises and hence improves success.
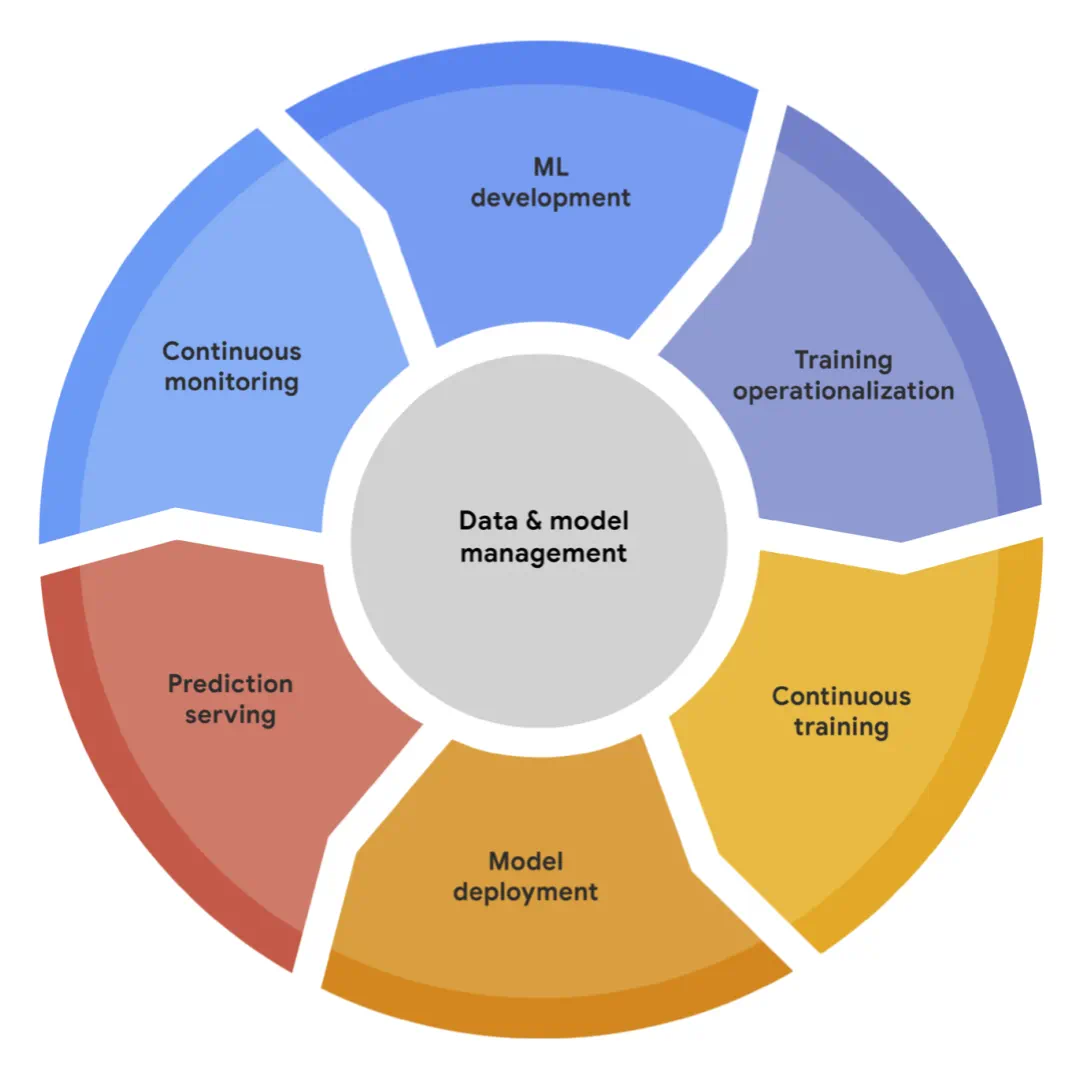
Google Cloud
Discussion on MLOps can not be complete without discussing the Big Three cloud providers with massive ML services stack.
Google is arguable the earliest and the biggest machine learning shop with the Vertex AI MLOps platform. It published a whitepaper titled Practitioners Guide to MLOps in May 2021. I am quoting the MLOps Lifecycle section from the whitepaper that describes the following parts:
- ML Development: Experimenting and developing a robust and reproducible model training procedure (training pipeline code), which consists of multiple tasks from data preparation and transformation to model training and evaluation.
- Training Operationalization: Automating the process of packaging, testing, and deploying repeatable and reliable training pipelines.
- Continuous Training: Repeatedly executing the training pipeline in response to new data, code changes, or on a schedule, potentially with new training settings.
- Model Deployment: Packaging, testing, and deploying a model to a serving environment for online experimentation and production serving.
- Prediction Serving: Serving the model that is deployed in production for inference.
- Continuous Monitoring: Monitoring the effectiveness and efficiency of a deployed model.
- Data and Model Management: A central, cross-cutting function for governing ML artifacts to support auditability, traceability, and compliance
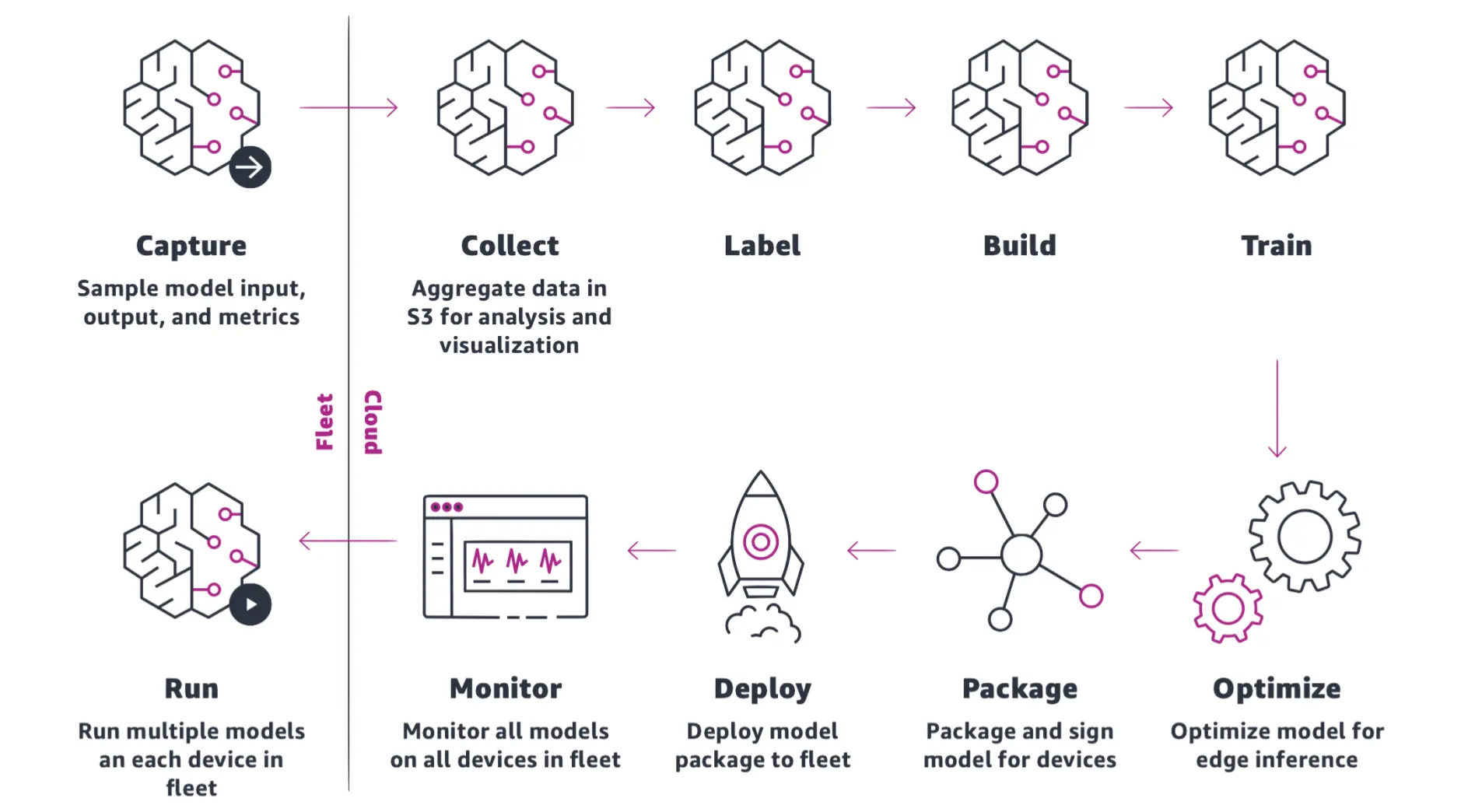
Amazon Web Services
Amazon was the first to offer an end-to-end MLOps platform: SageMaker. It published a Whitepaper “MLOps: Emerging Trends in Data, Code,
and Infrastructure, AWS Whitepaper” in June 2022, which defines a much simpler lifecycle. It is so simple that it is self-explanatory. It appears more like KDD and CRISP-DM than the DevOps loop.
Microsoft Azure
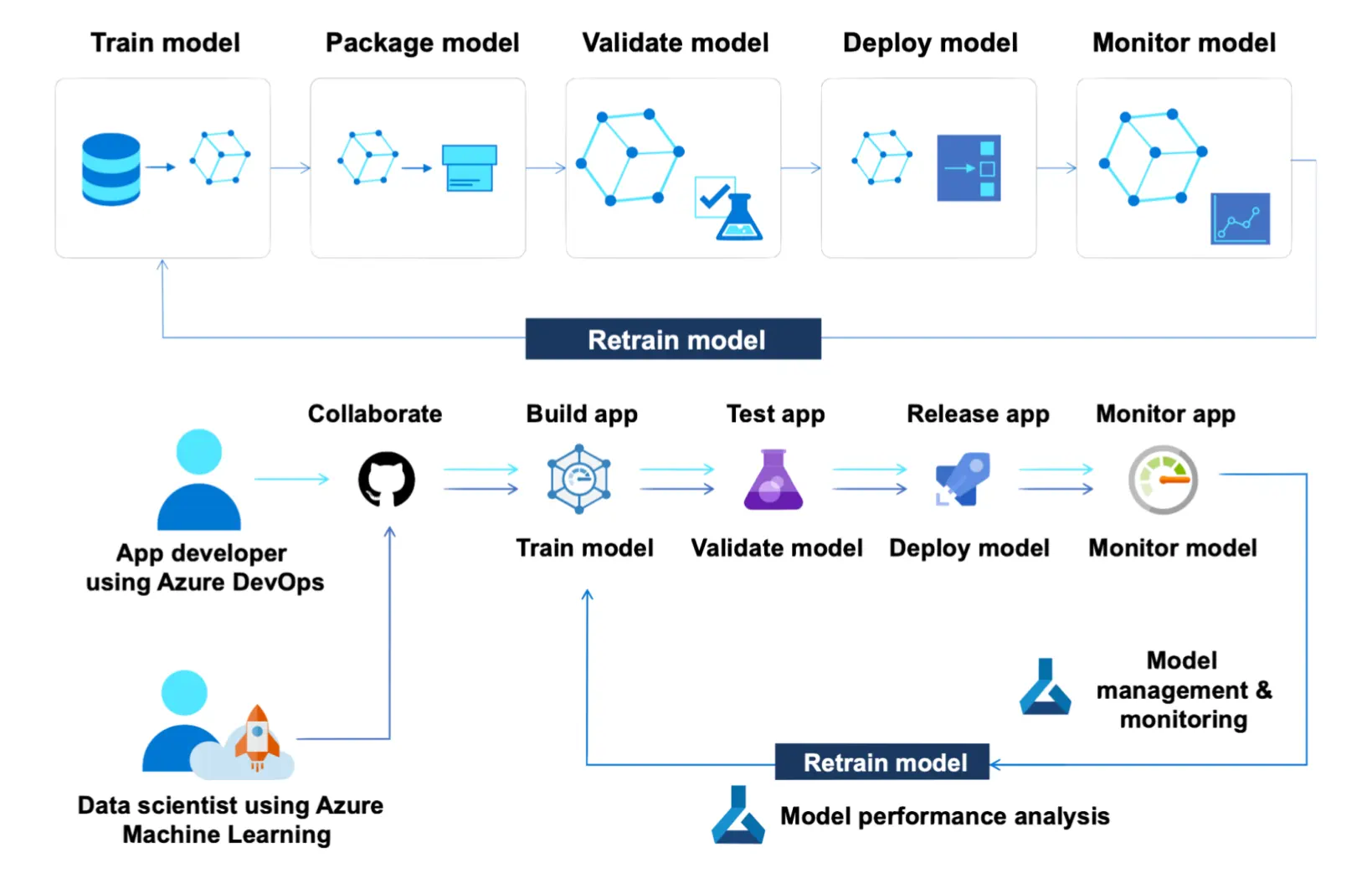
Microsoft also published an MLOps whitepaper “MLOps with Azure Machine Learning” in Aug 2021, defining the ML lifecycle and MLOps workflow. It is similar to AWS: simple and self-explanatory.
My take on ML Lifecycle
This article turned out to be much longer than I imagined. So thank you for your patience in reading it. If jumped here for TL;DR, then also thank you for caring to read my take.
First, what are the key characteristics of the ML lifecycle in the MLOps era?
-
Evolutionary, and not revolutionary. It should feel familiar to data scientists who are following CRISP-DM, OSEMN, or TDSP so far. It should also feel familiar to engineers following the DevOps infinite loop.
-
Optimized for recall, instead of precision. An easy-to-remember process is more likely to be followed and become part of a team’s vocabulary. For example, the DevOps infinite loop is not precise. Each step has several implicit back arrows to previous steps. Not everything after the Test leads to the Release. Failures go back to the Code or even Plan step.
-
Facilitates taking ML model to production. It should improve visibility and collaboration across a team of developers, data scientists, and data engineers, especially my philosophy of consolidating ownership, integrating early, and iterating often.
-
Flexible. It should allow parts of a team to choose their cadence. Data Science and software development are inherently different. Data Scientists can not produce incremental results daily. The goal of a lifecycle and process is visibility and cohesion, not a three-legged race.
Model Development Loop
If you ignore the deployment, the Model Development has its infinite loop just like the DevOps loop.
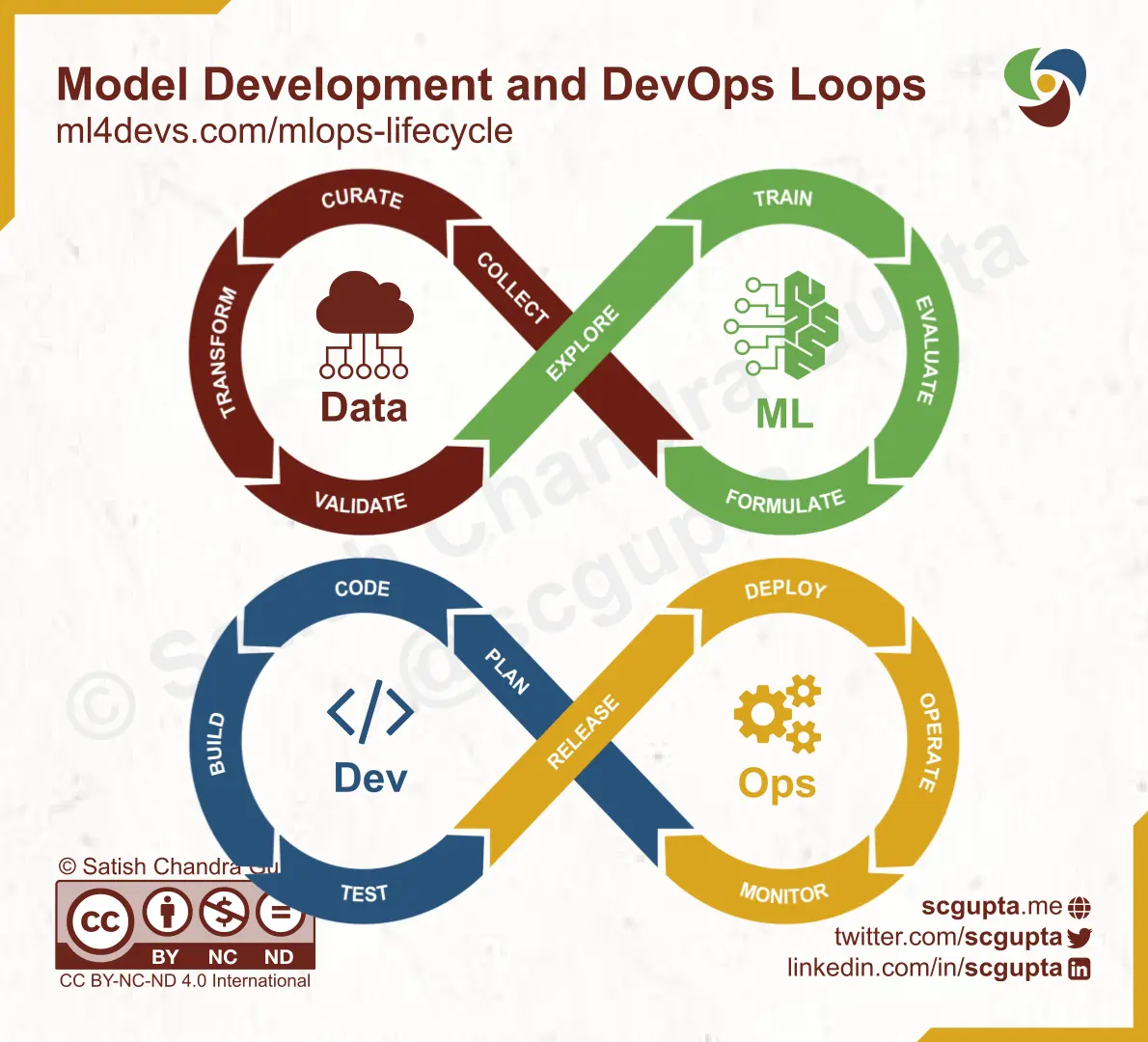
Think of CRISP-DM molded into an infinite loop. The steps in the Model Development loop are:
- Formulate a business problem in ML terms.
- Collect the necessary data from internal applications as well as external sources.
- Curate the data. Clean it, remove duplicates, fill missing values, label it, etc., and finally catalog and store it.
- Transform the data. Compute additional features, change the structure, etc.
- Validate the data. Implement quality checks, log data distribution, etc.
- Explore the data. Exploratory data analysis, feature engineering, etc. Most likely will lead to adding more transformations and data validation checks.
- Train a model. Run experiments, compare model performance, tune hyper-parameters, etc.
- Evaluate the model characteristics against business objectives. Any feedback may result in tweaking and formulating the ML problem differently.
Putting it All Together
Both data science and software development are meant to serve business goals. In ML-assisted applications, model design has to be mindful of how it will impact user experience and the constraints of the production environment. Similarly, the software design must include inconspicuously collecting user feedback vital for model improvement.
In ML-assisted products, model design and software design has a symbiotic relationship. The product design, the Plan step, has to consider both of these holistically, and that is the unifying step to join these two loops.
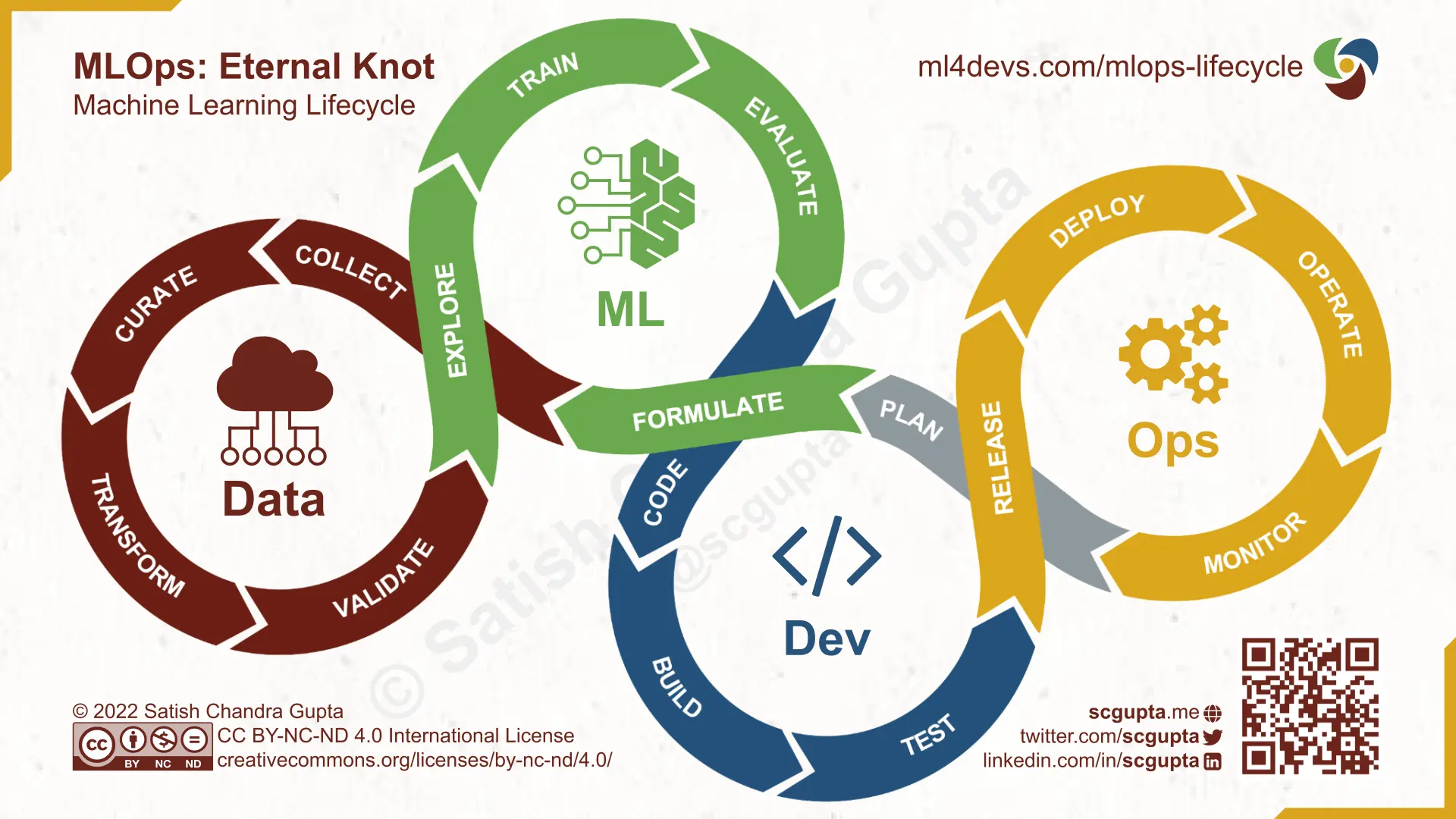
A unified MLOps Lifecycle gives visibility to all constituents rather than developers thinking of models as a black box that data scientists somehow train and toss over, and data scientists developing models that don’t serve the intended business objectives in production.
Data, ML, Data-ML, and DevOps loops can run in different cadences. I always try to first build an end-to-end application with a rule-based or dummy model, cutting off the Data-ML loop entirely. It works as a baseline, helps collect data, and also gives a context for data scientists to know how their model will be used.
Summary
This article described the evolution of the ML lifecycle across the Data Warehouse, Big Data Lakes, and MLOps eras. It also explained how it can be modified by joining model development and DevOps loops, and the advantages of doing so.
References
-
Knowledge Discovery and Data Mining: Towards a Unifying Framework by Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth, in KDD’96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, pp. 82–88, August 1996.
-
The CSP-DM Model: The New Blueprint for Data Mining, by Colin Shearer, in Journal of Data Warehousing, vol. 5, no. 4, pp. 13–22, 2000
-
A Taxonomy of Data Science (OSEMN Process) by Hilary Mason and Chris Wiggins, Sep 2010.
-
Microsoft’s Team Data Science Process (TDSP) Lifecycle.
-
Software Engineering for Machine Learning: A Case Study, by Saleema Amershi, et al., in ICSE-SEIP ’19: Proceedings of the 41st International Conference on Software Engineering: Software Engineering in Practice, May 2019. (PDF)
-
What Is MLOps? by Rick Merritt in Nvidia blog, 3 Sep 2020.
-
MLOps Principles, ml-ops.org, Retrieved on 8 Sep 2022.
-
The Modern MLOps Blueprint by Danny Farah, 24 Aug 2020.
-
Practitioners Guide to MLOps: A framework for continuous delivery and automation of machine learning. Google Cloud Whitepaper. May 2021.
-
MLOps: Continous Delivery for Machine Learning on AWS. AWS Whitepaper. Dec 2020.
-
MLOps: Emerging Trends in Data, Code, and Infrastructure. AWS Whitepaper. June 2022.
-
MLOps with Azure Machine Learning. Microsoft Whitepaper. Aug 2021.