In the previous issue, we examined the MLOps ecosystem. It is a lot more complex compared to traditional software engineering projects. In this issue, let’s understand the differences between:
-
Traditional programs and Machine Learning
-
Software Development Lifecycle and ML Project Lifecycle
We will also examine the evolution of software development and the friction in assimilating ML into software development.
Traditional Programs vs. Machine Learning
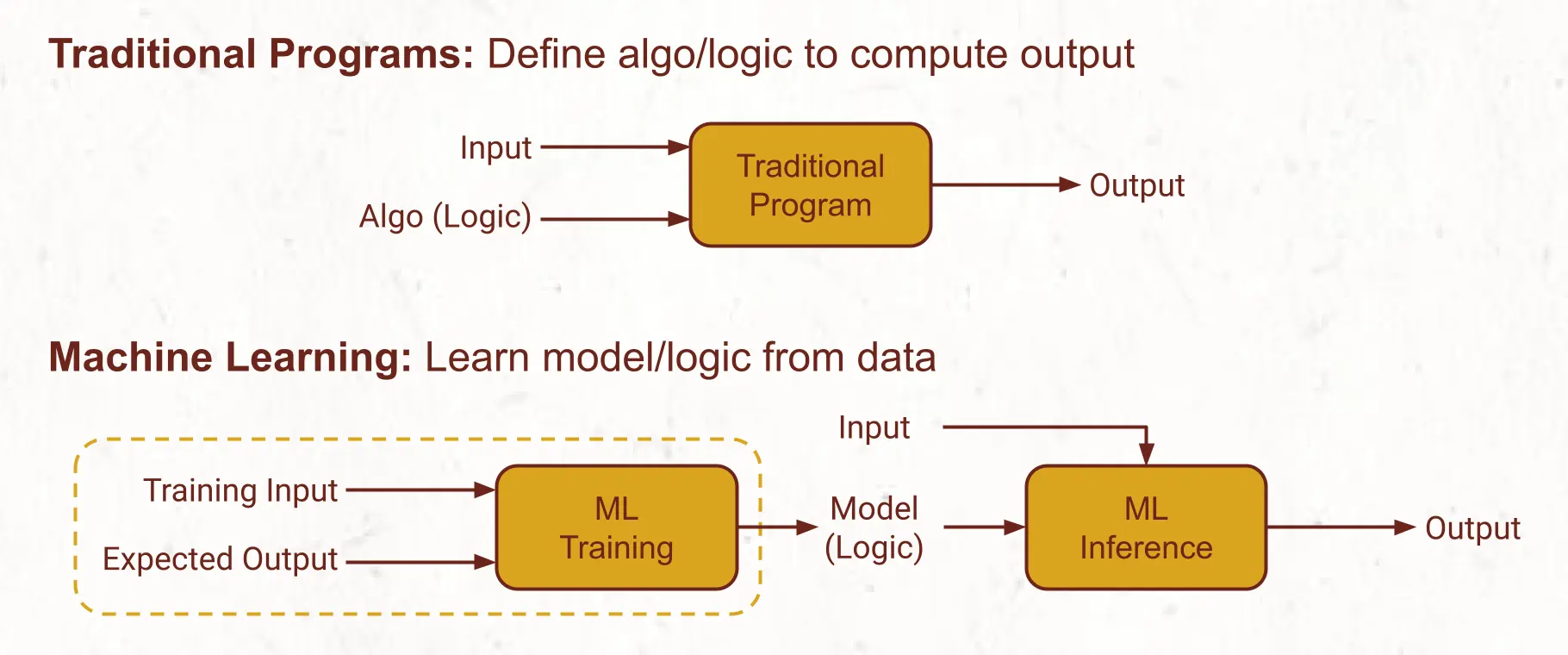
In traditional programs, a developer designs logic or algorithms to solve a problem. The program applies this logic to input and computes the output.
But in Machine Learning, a model is built from the data, and that model is the logic. ML programs have two distinct phases:
-
Training: Input and the expected output are used to train and test various models, and select the most suitable model.
-
Inference: The model is applied to the input to compute results. These results are wrong sometimes. A mechanism is built into the application to gather user feedback on such occasions.
This feedback is added to the training data, and this is how a model learns.
Let’s take the problem of detecting email spam and compare both methods.
Traditional programs detect spam by checking an email against a fixed set of heuristic rules. For example:
-
Does the email contain FREE, weight loss, or lottery several times?
-
Did it come from known spammer domain/IP addresses?
As spammers change tactics, developers need to continuously update these rules.
In Machine Learning Solutions, an engineer will:
-
Prepare a data set: a large number of emails labeled manually as “spam” or “not spam”.
-
Train, test, and tune models, and select the best.
-
During inference, apply the model to decide whether to keep an email in the inbox or in the spam folder.
-
If the user moves an email from inbox to spam or vice versa, add this feedback to the training data.
-
Retrain the model to be up-to-date with the spam trends.
As you can notice traditional programs are deterministic, but ML programs are probabilistic. Both make mistakes. But the traditional program will require constant manual effort in updating the rules, while the ML program will learn from new data when retrained.
Software Development Evolution
Before comparing the software and ML development lifecycle, let’s see how software and its development process have evolved. Every tech gets commoditized and becomes accessible: Scientists to Engineers to Technicians to Everyone.
Up to 1980: Scientist Era
Developing software was an art, and required in-depth knowledge of computer science. There wasn’t much of a process. But computer theory was highly developed.
1980–2000: Engineer Era
There was a massive expansion of personal desktop applications, and complex business applications built using multi-tier client-server architecture. Building software required engineering teams with broad computer science knowledge.
Waterfall Model was the first development process. It had a single pass of the Requirements, Design, Development, and Test phases. The project failure rate was high. Then the Iterative Development Model evolved having loops of these phases. High-risk issues were tackled first to avoid late failures.
2000–2020: Technician Era
Cloud applications arrived. These had mobile and browser front ends and distributed microservice architecture at the backend. Reusable components became available off-the-shelf as open-source software or pay-per-use SaaS. Assembling and developing complex applications became much easier and shorter.
With containers and DevOps, the process evolved into agile Continuous Integration and Continuous Delivery (CI/CD).
As software ate the world, it generated a lot of data. It fueled big data, analytics, data science, and machine learning.
2020 and beyond: Anyone Era
With No/Low-Code and Serverless, software development continues to be commoditized. It will become accessible to anyone and everyone.
Software Development Lifecycle vs ML Project Lifecycle
In the last 10 years, there has been an increasing number of ML-assisted applications operating on big data, with Edge + Cloud architecture. ML project development is often separate from the rest of the software development.
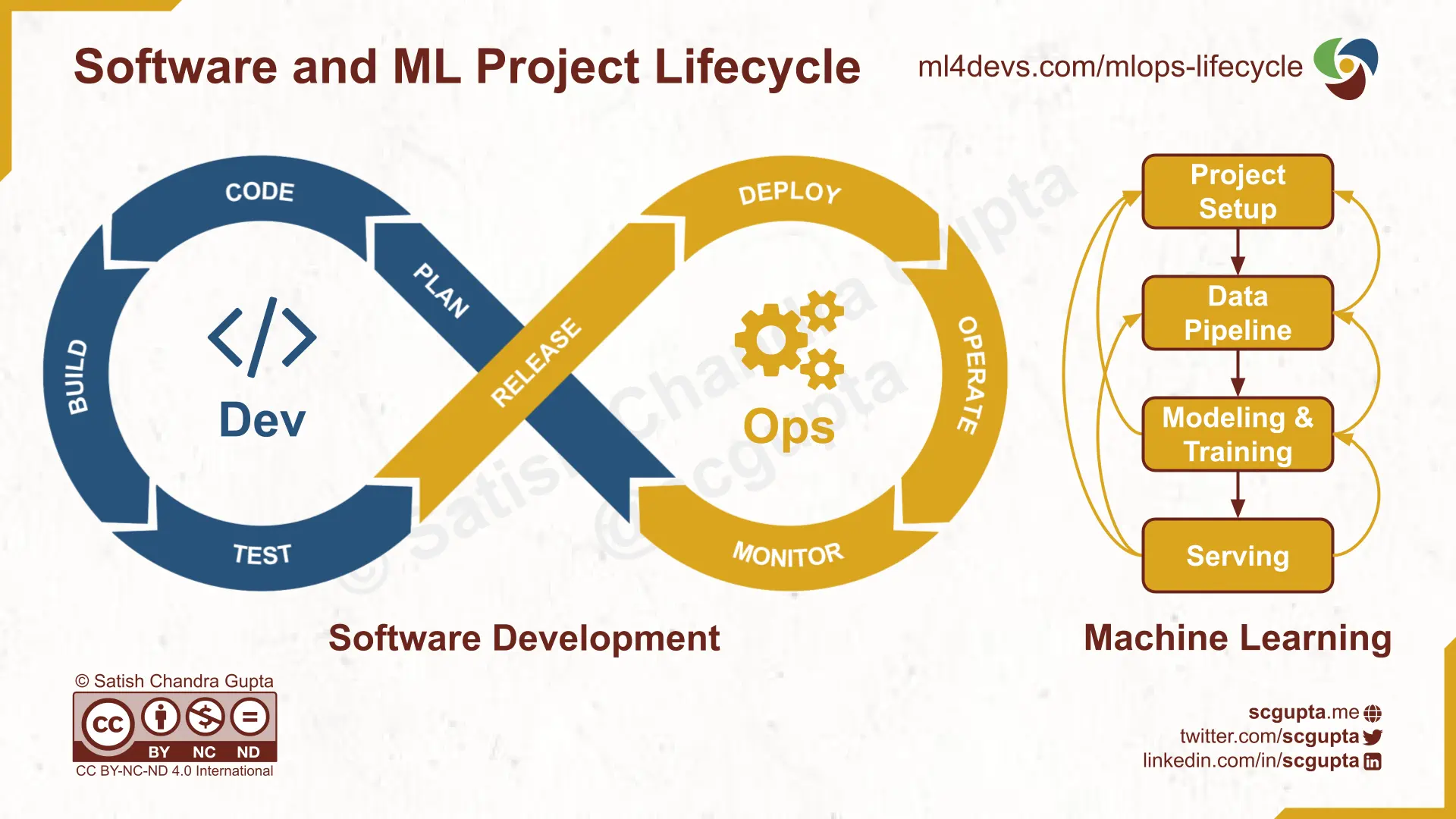
There are two common sources of friction:
-
Not Iterative: While the software development follows the CI/CD DevOps loop, Machine Learning Project Lifecycle is more like the waterfall model. Typically a data scientist develops a model and then hands it over to an engineer for implementing it in production.
-
Not Incremental: Minor tweaks in requirements can force the data scientists and ML engineers to start over from the data collection and pipeline setup. Development cost is not proportional to the changes in the requirements.
When it was transitioning from the waterfall to the iterative process, the software development lifecycle looked similar to how the ML project lifecycle is now. Software development effort estimations were equally unpredictable, and projects had controversially high failure rates.
As ML tooling matures, ML project development is transitioning from waterfall silos to iterative, and from scientists era to engineers era.
The Road Ahead
This is not the first time software development is facing a major paradigm shift. Moving to hyper-scale, distributed applications on the cloud was also a fundamental shift in software development. Developers figured out CI/CD to manage requirement changes and deploy cloud applications with unprecedented frequency. The same will happen with ML too.
It takes time to impart tribal knowledge of an organization and a business domain. It takes effort to become an expert in developing production-quality real-world applications. If developers can do that, I bet they can also adapt to building ML apps.
Further Readings
Software 2.0 and Deep Learning is Eating Software provocatively speculate on the impact of deep neural networks on software. The road to Software 2.0 is a concise and more balanced take on the same. I want to add that deep learning — and even machine learning — is not suitable for all applications. You may also want to check a previous issue on “To be agile, or not to be, that is the question”.