
A data model organizes data elements and formalizes their relationships with one another. In database design, data modeling is the process of analyzing application requirements and designing conceptual, logical, and physical data models for storage. However, data storage is only one, albeit an important, aspect of microservices.
There are three related but distinct data models in a microservice for:
-
API Data Model for interactions: It defines the schema of data payload that can be sent to or is received from the endpoints of a microservice. Also known as communication or exchange data model.
-
Object Data Model for computations: It is designed for efficient business logic implementation. Also known as application data model or data structures.
-
Storage Data Model for persistence: It defines the schema of various, occasionally redundant, data stores and caches.
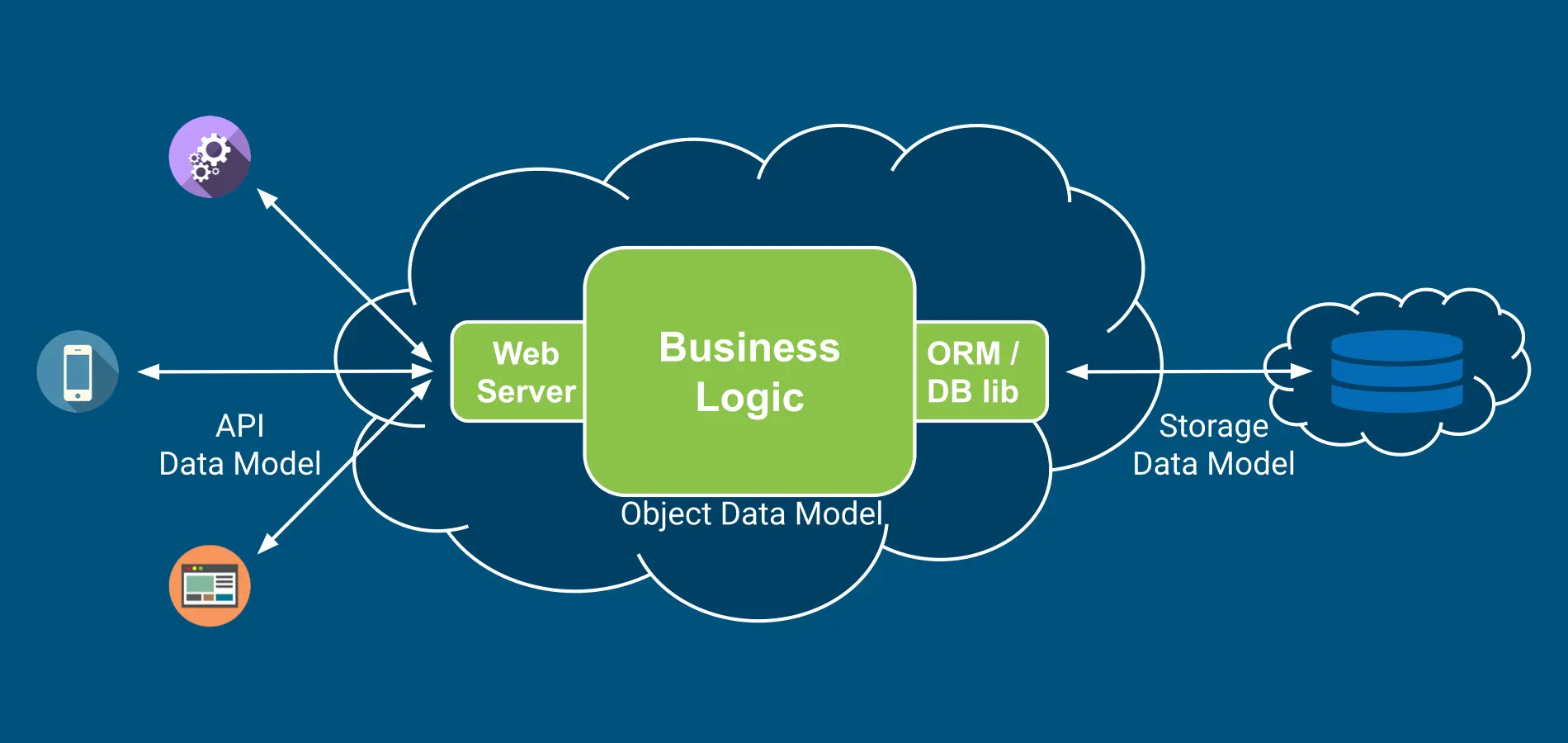
Due to shared application concepts, all three data models will have similarities. But depending upon the application, the structure and the level of details may vary.
In this article, you will learn about designing and testing these data models.
Why Data Models
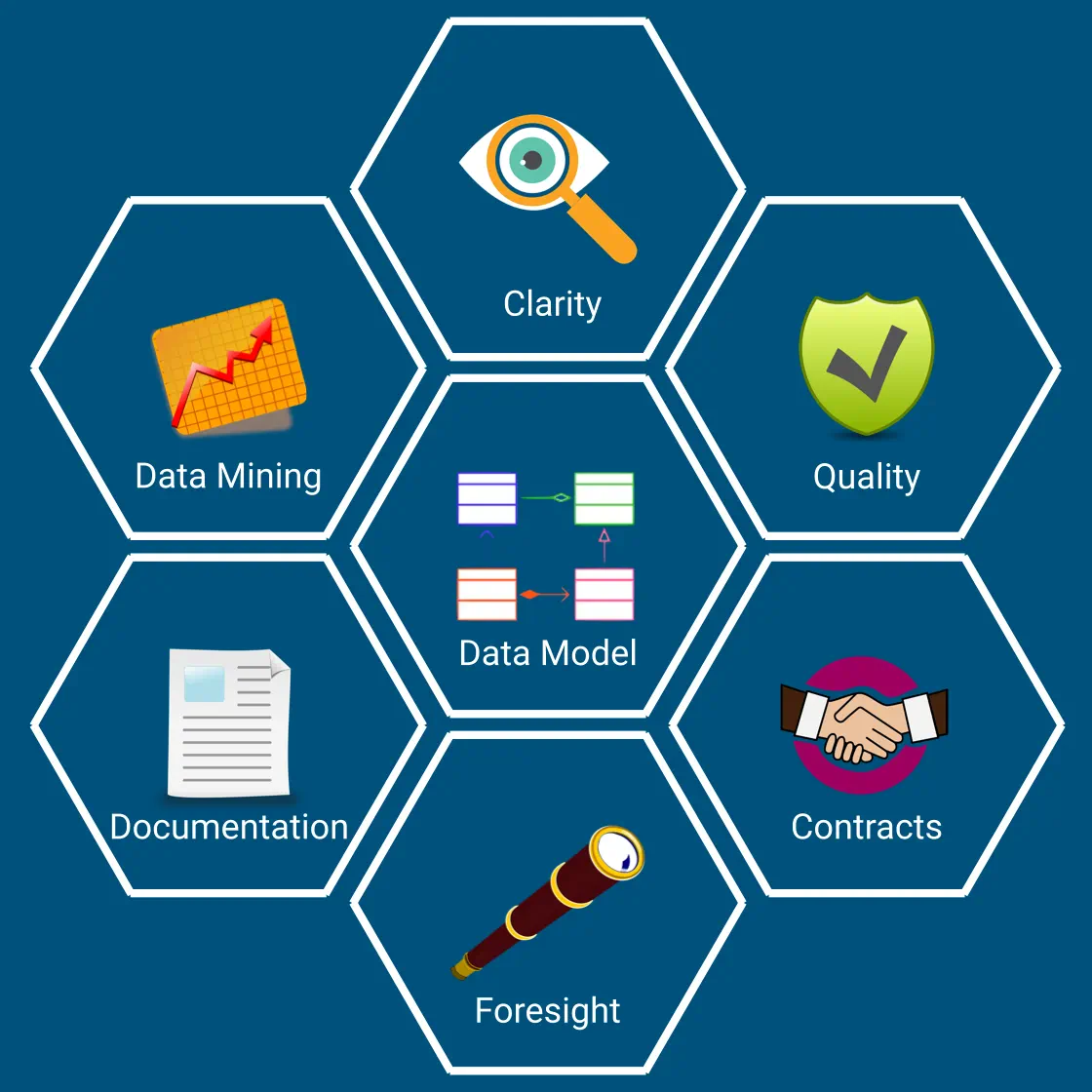
Before jumping into designing data models, let’s examine the benefits first.
It brings clarity
Defining a data model establishes and consolidates a common vocabulary. Having it all in one place helps in grasping the full picture quickly.
improves quality
With common vocabulary and consolidation, it becomes feasible to argue about it in totality. It is easier to identify gaps, redundancies, errors, and inefficiencies.
It establishes the contracts
While debating on data, its structure, transformations, and flow, several questions crop up, and clarifications are sought. The requirements and specifications become clearer. The data model becomes part of the contract.
It triggers foresight
With clarity on the data model and data flow, it becomes easier to think through across the full system and foresee problems. That, in turn, helps in identifying, decoupling, and localizing the concerns. The data model leads to the initial design blueprint.
It improves documentation
Data models capture important ideas and abstractions in the application. It unambiguously defines the data being exchanged across application and component boundaries. Such documentation reduces the acclimatization time needed for a new customer or engineer.
It seeds data mining
The data model serves as the catalog for analytics and data science. Data scientists do not have to comb through the application code to understand the structure and meaning of the data.
API Data Model
API Data Model is for defining the data being exchanged while interacting with a microservice. It is the schema of the data payload. It usually is a subset of the Object Data Model. However, the structure is designed to optimize the size of the data payload, and the time taken in serialization, deserialization, and validation.
There are several choices to define API Data Model for a microservice.
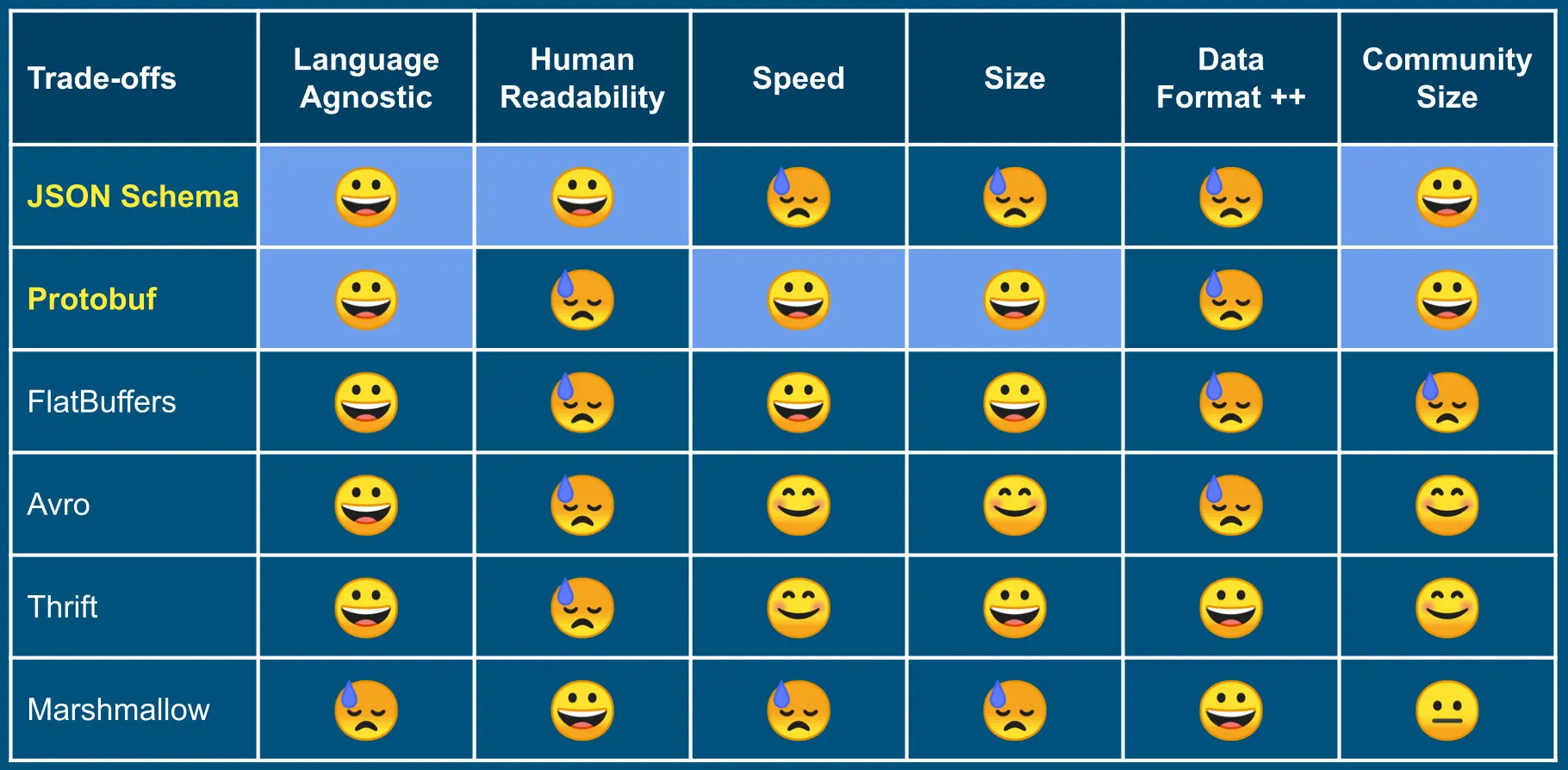
JSON Schema
JSON (JavaScript Object Notation) is probably the most popular data-interchange format. It is a text format, so it is easy for humans to read and write. It is lightweight and independent of any programming language. There are libraries for JSON in all popular programming languages, e.g., json Python package.
JSON Schema is a standard to define the acceptable JSON structure. you can validate a JSON against a given schema (in Python, using jsonschema package).
The biggest benefit of JSON is that it is human-readable. That is its drawback too. It makes it space inefficient compared to binary formats. Some of that inefficiency can be mitigated using HTTP compression encoding.
Many databases support the JSON value type. The data is stored as a (possibly compact) string. But unlike strings, fields are accessible in query through hierarchical paths.
JSON is apt when data payloads are not large.
Protobuf (Protocol Buffers)
Protobufs are “Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data.” It is a binary data format. You define the schema once in a .proto file, and then compile it into your favorite programming language.
The advantage of Protobuf is that it is faster, smaller, and typesafe. Protobuf schema is backward compatible. As schema evolves, the generated code will still be able to parse old buffers. The main downside is that Protobuf data is not human-readable. You need the schema code to parse the buffer.
When your data payload is huge, Protobuf offers significant speed and bandwidth benefits.
FlatBuffers
FlatBuffers is another cross-platform serialization library from Google. It has an advantage over Protobuf. The hierarchical data in FlatBuffer can be accessed without deserializing the whole buffer. It is strongly typed, fast, and takes less memory.
It suffers the same disadvantage as Protobuf. It is not human-readable, and also the community is small.
Avro
Apache Avro is a fast binary data serialization system. Unlike Protobuf and FlatBuffers, it stores schema along with data. It has dynamic typing and code generation is optional. Since it is a binary format, data is human-unreadable.
Thrift
Apache Thrift was developed at Facebook. It is a framework for defining data types and service interfaces. It generates code for Remote Procedure Call (RPC) clients and servers in a wide range of languages.
It is more than a data exchange format. Though, the data format is binary.
Marshmallow
Marshmallow is also more than just a data exchange format. It is an “Object Relational Mapper (ORM) / Object Document Mapper (ODM) / framework-agnostic library for converting complex data types, such as objects, to and from native Python datatypes.”
The native Python types are converted to JSON. So, the underlying format is JSON. But the schema is defined in code by inheriting from the Marshmallow Schema class.
It has the benefit of JSON being human-readable, and the code between schemas can be shared.
However, it has a serious disadvantage compared to JSON Schema and other alternatives. The schema is not declarative; it is not in one concise definition file. The details are littered in code. JSON Schema or the .proto file can be easily shared with API users to communicate data payload definitions.
Implementation
Based on the characteristics of the alternatives, JSON Schema and Protobuf offer the best trade-offs for most situations. If the data payload is small, JSON has the benefit of human readability without much speed and size penalty. For big data payload, Protobuf savings are attractive.
In this tutorial, we are using the example of an address-book service. Data payloads are small, so we will use JSON Schema.
Get the source code:
|
|
The JSON schema for the API data model is in schema/address-book-v1.0.json. It is too long to reproduce here. Writing JSON schema is quite simple, you can learn it from this short official quickstart guide.
Validating a JSON schema and contents of a JSON file is straight forward:
|
|
The JSON samples to test the API data model are in data/addresses/*.json. The API Data Model can be tested in isolation by writing validation tests for the sample test data. This has the added benefit of ensuring that incorrect data does not cause other test failures. The test tests/unit/address_data_test.py validates that sample data files conform to the API data model defined in the address-book JSON schema.
|
|
Object Data Model
Object Data Model is designed to serve the needs of the business logic. It is the data structures used in implementing an application. It is the classes in the code, which are instantiated and operated on.
The object data model will be similar to, but most likely will not be the same as, the API or storage data model. It will depend on the complexity of the application and performance requirements.
Generating Model from Schema
In the simplest situation, it may be the same as the API data model. In that case, it is ideal to generate it from the JSON Schema. There are tools like Python JSON Schema Objects, Warlock, Valideer, that generate POPO (Plain Old Python Object) classes from a JSON schema.
Python code can be generated from Protobuf too.
Issues with using generated POPO
These tools generate a simple structural mapping from the schema to Python classes. That may not suffice all your needs:
-
There are additional application constraints that can’t be expressed in the schema. It is possible to do it in a post-processing pass over the deserialization output. But it is better to keep these constraints within the respective data model classes.
-
There are methods and class invariants that must maintain during the life of an object. You can’t add these to the generated code. Otherwise, it will be overwritten on the next schema update and code generation.
-
There is a polymorphic class hierarchy in the object data model, but the schema tool can’t infer and generate it.
-
Some of the data members should be modified only through operations in a class, and not directly. Generated code does not offer that control.
You must consider one serious risk of using generated POPO as the data model for your business logic. If the generated POPO changes significantly, the blast radius includes the whole application. It may break the code by causing exceptions, or worse, by introducing silent bugs. This can happen because of:
-
changes in your schema,
-
changes in the way the schema tool generates code, or
-
you decide to change the schema tool.
On such occasions, changes will percolate all over in the business logic. You will have to thoroughly test the whole application.
Handcrafting Data Model
A handcrafted data model offers you full control to design it precisely for your needs. It limits the blast radius to itself. In case of any change in schema or schema tool, only the data model needs to be updated and tested.
There are two implementation tactics.
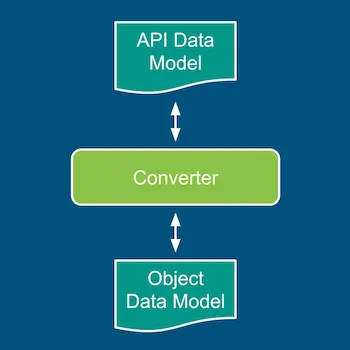
Conversion: Convert from/to your schema tool format. For example, parsing a JSON string produces a value of native Python type (a scalar, list, or dictionary). Convert it to an object of a type/class in your data model.
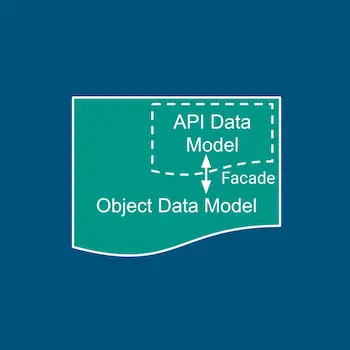
Facade: Build a thin facade over the POJOs generated by your schema tool. Data Model classes encapsulate POJOs, and implement functions by manipulating the POJOs.
The conversion tactic is simpler but has a mandatory conversion cost. The facade tactic can be complex but quite likely more efficient.
For schema tools (like JSON schema) that creates native Python types, conversion tactic is preferable. Implementing facade over nested lists and dictionaries can be tricky. For schema tools (like Protobuf), implementing facade may work better.
A handcrafted data model offers you the option of switching the tactic later. Just preserve the interface of the object data model.
Implementation
The object data model is implemented in addrservice/datamodel.py. It uses the conversion tactic and implements from_api_dm and to_api_dm methods. Here is one of the classes.
|
|
If the tactic is changed to the facade, the AddressEntry class will have only one data attribute, say, _api_dm. All property methods will be implemented by accessing and manipulating that attribute. The from_api_dm and to_api_dm methods will call the constructor with _api_dm argument and return the _api_dm respectively. Since the interface of AddressEntry will remain the same, the change will not percolate to the rest of the system.
The key is to define the object model interface for the business logic of the application.
The Object Data Model is the bedrock of business logic. It must be tested thoroughly with 90+% code coverage. Code coverage gives confidence that this foundation is not having bugs.
Unit tests should target the data model interface used by the business logic. Automating these tests buys insurance against future changes in the schema and tooling.
|
|
Storage Data Model
The storage data modeling is the well-established process of iterating over conceptual, logical, and physical data models. There are plenty of resources on Object Relational Mapper (ORM). Instead, I will discuss our testing tactics when it comes to storage.
With databases, only end-to-end tests can truly test the functionality. In unit and integration tests, the database calls are mocked. Mocking causes difficulty for deep integrations tests. These tests perform a sequence of related service requests and assert business invariances.
For each of our storage data models, we implement an in-memory data store, along with the actual data store. There are tests using each of these. Tests using actual data store mock the database calls.
A set of integration tests use the in-memory database. These can assert complex business logic with the help of the database state.
Sometimes, we also have an implementation using file-system as storage. It is inexpensive to implement and very useful while debugging.
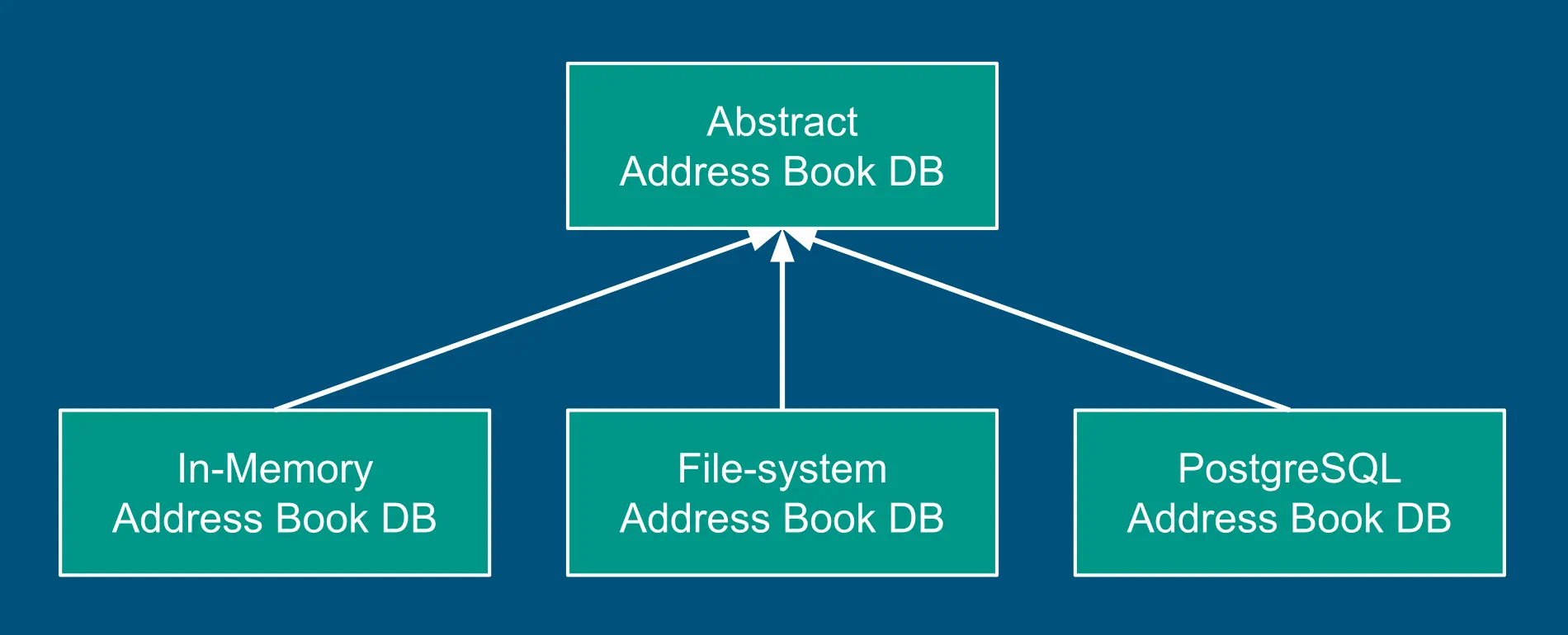
Storage data model selection is controlled by the config of the microservice.
|
|
A DB class encapsulates details of that specific storage data model. Notice that AbstractAddressBookDB does not expose the storage model. Its functions take and return the Object Data Model values. Business logic knows only the Object Data Model. This decoupling is simple to achieve. It allows a different database to be hooked without touching business logic.
|
|
Full implementations are in addreservice/database/addressbook_db.py.
Stitching it together
Every microservice consists of the following layers. Each layer has orthogonal and atomic responsibilities.
-
Web Framework (
addrservice/tornado/app.py):
Its role is to understand HTTP requests. It uses only the API data model. It invokes functions in the service interface. -
Service Interface (
addrservice/service.py):
Defines the service interface independent of any web framework. It either translates the API data model or puts a facade to convert it to the object data model. It then invokes appropriate functions in the business logic. -
Business Logic (
addrservice/datamodel.py):
The business logic is as complex as the application. In this example, it is kept minimal by design. It uses only the object data model. It invokes the functions of the abstract storage data model to persist data. -
Storage Data Model (
addrservice/database/addressbook_db.py):
The storage data model interface takes in and returns the Object Mata Model values. It may use an ORM and database client lib. An implementation of the interface is selected based on the config file.
|
|
Run linter, type-checker, and tests with code coverage:
|
|
Summary
There are three types of data models in microservices:
- API Data Model is designed to serve the needs of clients of the service. JSON schema and Protobuf are most popular for small and big data payloads.
- Object Data Model is designed to serve the needs of the business logic in the service. It is the most pervasive data model in the application. It is prudent to keep its interface independent of any other data model.
- Storage Data Model is designed for efficient data storage and retrieval. Encapsulate it in an API with parameters and values of object data model types. An in-memory implementation facilitates rigorous testing of business logic.
Tutorial – Python Microservices with Tornado:
- Choices, Key Concepts, and Project setup
- Build and Test REST endpoints with Tornado
- Effective Canonical Logging across Services
- API, Object, and Storage Data Models