MLOps is a hot topic and everyone seems to be talking about it. I have been reading quite a bit of material, but I will share what I have learned so far.
Why MLOps
Considering quite a lot of ML projects fail to go to production, MLOps is for successfully managing Machine Learning lifecycle and avoiding that fate.
To set the context for MLOps and ML pipeline, let’s step back and recap my three percepts from software engineering that we can apply to ML:
- Consolidate Ownership: Cross-functional team responsible for the end-to-end project.
- Integrate Early: Implement a simple (rule-based or dummy) model and develop end-to-end product feature first.
- Iterate Often: Build better models and replace the simple model, monitor, and repeat.
Consolidate Ownership
The Modeling and Engineering silos can be avoided by setting up a cross-functional team of product managers, developers, data engineers, and data scientists that is responsible for the feature end-to-end.
It improves communication. Data Scientists are in tune with business needs and production constraints, and developers get to know the nuances in utilizing the model.
Integrate Early
Do not jump into making an ML model. First, make a skeleton application end-to-end. For the ML component, just implement a dummy baseline rule-based system. It is okay if it is not accurate.
Seeing how your ML model will be consumed in a barely functioning system is a superpower.
For the ML component, design application-centric APIs. Even if you have a strong sense of what model you are going to use, resist spilling the model specifics into the APIs. A nice encapsulation will make it easy to swap and experiment with the models.
Iterate Often
Integrating early with a dummy baseline model also decouples ML from the development of other parts. While some developers can iterate over and enrich the skeleton application, ML engineers can work on models and always have an end-to-end system to test and experiment with.
This integration also gives you a baseline for benchmarking evaluation metrics. There are four important metrics:
-
Business Success: Impact of the product feature on the business (e.g. rate of recommended product being bought). Either implicitly through user actions or by designing a way for users to give feedback.
-
Model Performance: Benchmark the effectiveness of the model.
-
Latency: Time is taken in model inference. A perfect model that tests users’ patience is a bad model.
-
Data Drift: Used after the deployment to monitor if data distribution of data encountered in wild is shifting.
With careful design, it is possible to have a high product experience despite not-do-high model performance. For example, showing search or recommendation results only when confidence is above a certain threshold, or showing top 3 suggestions instead of one, can lead to higher user satisfaction. Careful product design plays a huge role in ML success.
ML Pipeline
When someone says ML pipelines, we mostly think about ML model training pipeline:
- Data Ingestion: Collect and consolidate data from multiple sources.
- Data Preprocessing: Clean, curate, and extract features.
- Model Training: Train model alternatives.
- Model Evaluation: Track performance metrics.
- Result Logs: Record all details for comparison and reproducibility.
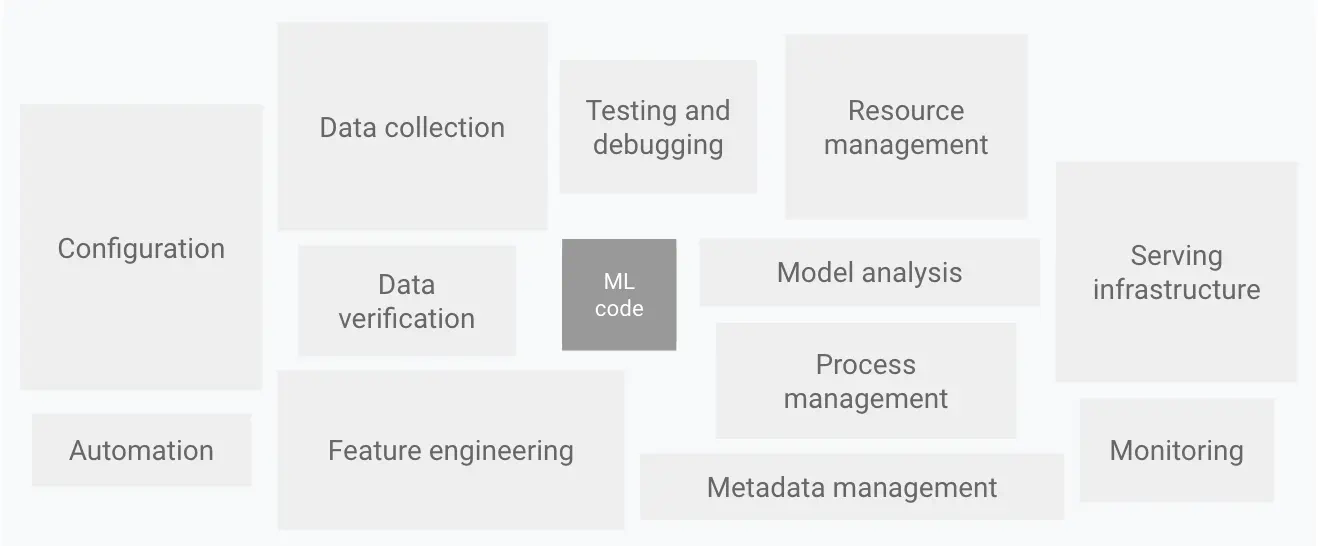
But ML pipelines in production are a lot more than training. Google has been running ML models on a large scale probably for the longest, and they have published their best practices in automating machine learning pipelines. They confirm that only a small fraction of a real-world ML system is composed of ML code. You probably would have seen this diagram:
The automated pipeline needs to be built for:
-
Continuous Integration: Tests for not just code but also for validating data, data schemas, and models.
-
Continuous Delivery: Deploy not just one (ML prediction) service, but an ML training pipeline that should automatically deploy an ML prediction service when desired.
-
Continuous Training: New and unique to ML for automatically retraining and serving ML models.
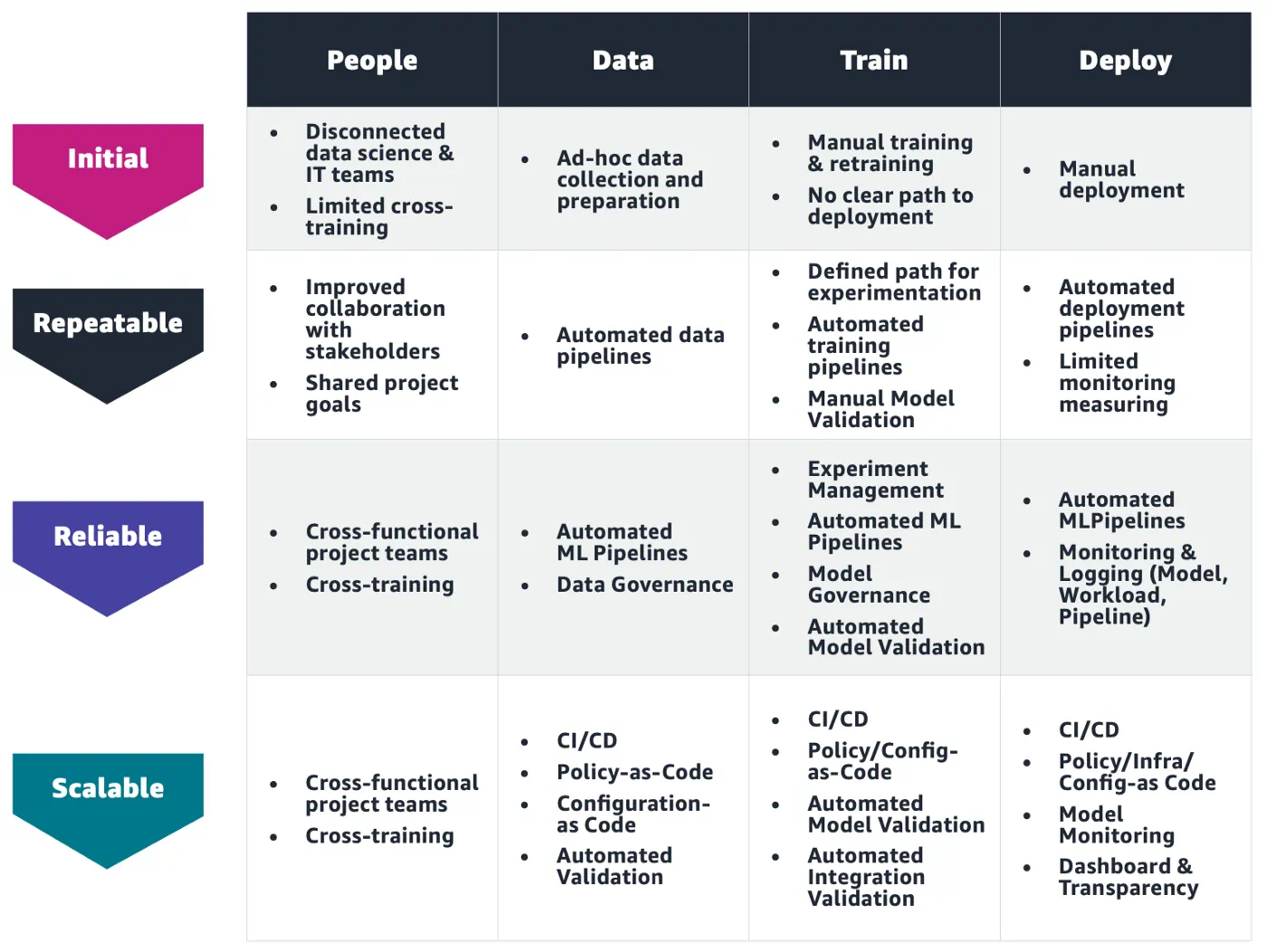
ML Maturity Levels
That article also defines MLOps maturity levels:
-
Level 0: Manual process: Train, and deploy ML models manually
-
Level 1: ML pipeline automation: Automated pipeline for continuous training, and continuous delivery of the ML prediction service, however, the ML pipeline is deployed manually.
-
Level 2: CI/CD pipeline automation: Automated ML pipeline deployment.

Microsoft has slightly different takes on MLOps maturity levels. Microsoft defines the following MLOps maturity levels:
- Level 0: No MLOps
- Level 1: DevOps no MLOps
- Level 2: Automated Training
- Level 3: Automated Model Deployment
- Level 4: Full MLOps Automated Retraining
Amazon organizes MLOps Maturity Model slightly differently too:
MLOps Tooling
Just a conceptual pipeline does not suffice. We need tools to implement the pipeline. There has been an explosion of MLOps tools. I am listing here only a few prominent alternatives:
Tools are evolving very rapidly. TFX is more comprehensive and complex. MLFlow and MetaFlow are quite mature and not as complex as TFX. It is also common to combine multiple tools with Airflow and Kubeflow.
How to navigate with MLOps-info overload
My apologies for so many links in this issue. I hope that it will be useful in the future, and you may return to it at a later date.
It is normal to feel overwhelmed in the maze of tools. Just as you can start with descriptive analytics instead of the most complex ML, you do not need to start at Level 2 of ML maturity. Starting at Level 0 and slowly progressing to higher levels is a good plan.
Being aware of the ML maturity levels will help you in crafting your path. So, you can skip all the links above, but this one article I highly recommend “ MLOps: Continuous delivery and automation pipelines in machine learning.” It is quite easy to understand and gives a broad overview of MLOps pipelines. There is an interesting video series discussing this article in MLOps Community.
Reading List
-
A detailed article on organizing machine learning projects, and Cookiecutter Data Science project directory structure.
-
A lesson in the Full Stack Deep Learning course on Setting up ML projects.
-
An intro to designing scalable and efficient data pipelines on the cloud.
-
For pipeline on Apache Spark: ML Pipelines in Spark MLlib.
-
If you are comfortable with ML modeling, this is a highly technical lesson on setting up a baseline.